I like to think of myself as the anti data scientist, or the troll of data science. I do my posts for me (and to entertain my one loyal reader, Sam). If I find some data to play around with and want to make a funky chart, then I can't be stopped. That's why I decided to make a word cloud of words from a Bank of Canada press release. I also decided to use R. On top of that, I am using R inside Jupyter. A slew of faux-pas.
People in the data world tend to hate word clouds. Some data scientists hate them so much that they have the urge to write an entire article about why Word Clouds are Lame. I only skimmed this article to find a funny quote. Here is one: "word clouds [are] the pie chart of text data." So if people don't like it, of course I'm going to create it.
Also, I agree that pie charts kind of suck, but I have worked in places where pie charts are the only natural, easily-digestible choice. Maybe I will create 100 pie charts for my next post.
Packages¶
I'm using pdftools to grab the text from the PDF press release, tokenizers to break up the text into sentences and words, corpus to analyze the words and wordcloud to create the word cloud. I threw tidyverse in there because you basically need it for everything in R.
I think technically you should only have to use one of tokenizers or corpus but I found that using both gave me cleaner data.
library(pdftools)
library(tidyverse)
library(tokenizers)
library(wordcloud)
library(corpus)
Download PDF, extract text and tokenize¶
url = "https://www.bankofcanada.ca/wp-content/uploads/2019/10/fad-press-release-2019-10-30.pdf"
file_name = "fad-press-release-2019-10-30.pdf"
download.file(url, file_name, mode = "wb")
I apply the tokenize_sentences and tokenize_words functions from the tokenizers library to the raw text to break it into sentences and words. I've picked out sentences 3 to 26 since those are the body of the text. Sentences 1 and 2 contain the letter head information and the title, so they're not useful here. Sentences after 26 are also not useful. They give information on the next press release date and the Bank's contact info.
sentences <- pdf_text(file_name) %>% tokenize_sentences()
txt <- sentences[[1]][3:26]
txt <- txt %>% tokenize_words()
Below is the result of tokenizing the full text and then the sentences into single words. Notice that the case has been changed to lower. There are still some things in there like numbers that we want to get rid of. For that I use the corpus package.
txt
Convert to corpus data frame¶
The corpus package makes working with text data easier. I've decided to apply corpus functions to my already-tokenized text as I found that just using the tokenizers library wasn't enough. Corpus allows you to create corpus data frame objects using corpus_frame. The corpus library still lets you pass other object types as inputs, such as a regular data.frame. However, passing a corpus data frame gives you more functionality, such as the ability to apply the text_filter function, which filters out things like punctuation and numbers. See this vignette for an introduction to corpus.
Important note: the corpus_frame function expects the input to have a column called text.
names(txt) <- paste("page", seq_along(txt), sep = "")
# convert to normal data frame
df = data.frame(text)
for (item in txt)
{
df_temp = data.frame(text = item)
df <- rbind(df, df_temp)
}
# convert to corpus data frame
data <- corpus_frame(df)
Filter out numbers and punctuation¶
The default options for drop_number and drop_punc are set to FALSE, so we need to change those in the text_filter properties:
text_filter(data)$drop_number <- TRUE
text_filter(data)$drop_punct <- TRUE
Create a list of Bank-specific stop words¶
Stop words are common words, such as "the", that we need to instruct the program to ignore. Bank of Canada press releases tend to use a handful of words common to economics so I've decided to create a custom stop word list to filter them out.
boc_stopwords <- c('per','cent', 'percent','rate','rates','bank',"bank\'s",'canada',
'monetary','policy','report','mpr','governing','council','year',
'january','february','march','april','may','june','july','august',
'september','october','november','december')
Tally word counts¶
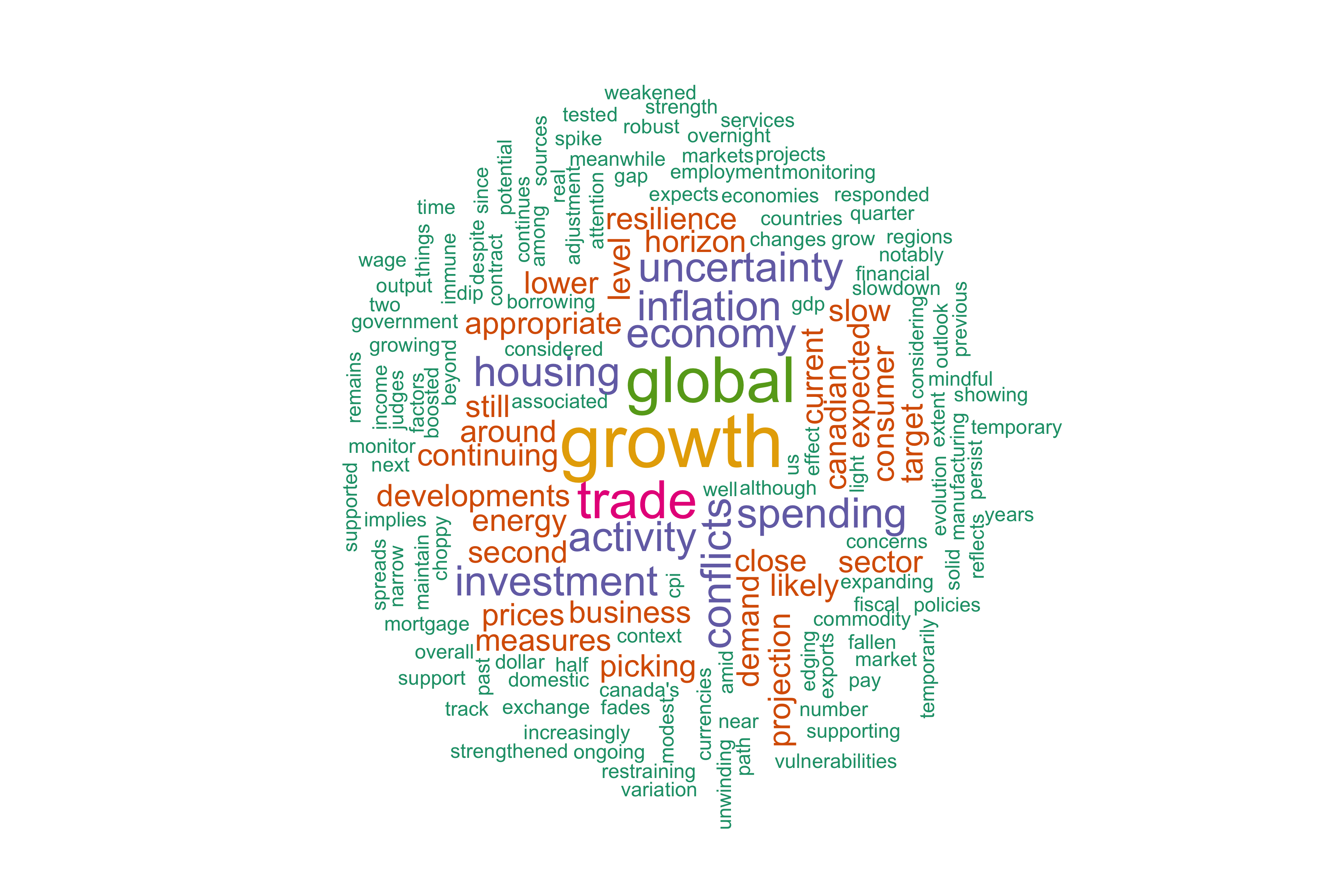
Corpus has a term_stats function that counts all the instances of words. Below we see that "growth" is the most frequently used term. Coming from a central bank, that's not suprising.
term_stats <- term_stats(data, subset = !term %in% boc_stopwords & !term %in% stopwords_en)
head(term_stats)
Create word cloud¶
# save image
png("oct2019.png", width=12,height=8, units='in', res=300)
wordcloud(words = term_stats$term, freq = term_stats$count, min.freq = 1,
max.words=500, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(6, "Dark2"))